This guide explains how to prevent most common web crawlers from redundant utilization of the visitor traffic log and appearing on your website tracking reports.
A web crawler is an Internet website scouting bot (script) that periodically scans websites typically for the purpose of indexing web pages. Other web bots extract information from websites for the purpose of data mining.
📈 Sign Up now to instantly track website visitors IPs!
Blocking website crawlers from being logged by the Visitor Tracker
Blocking a website bot from being logged by the tracker does not block the bot from accessing a website but rather tells the tracker system to ignore bots visits.
![]()
- Navigate to “My Projects” page. Locate the project that you need to stop logging web crawlers and click on the “edit” link.
- Find the “Log Filter” drop-down menu and select “Do NOT Log Robot Visits”
- Scroll to the bottom of the page and click on the “Update” Button.
On “My Projects” page, you can now visually confirm that the feature is enabled by observing a corresponding robot icon displayed under the status screen. 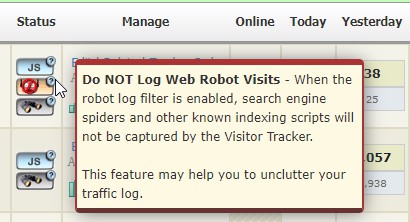
If you need to completely stop tracking visitor activity, you can temporarily enable a “Suspend Tracking” option.
📈 Sign Up now to instantly track website visitors IPs!